Neural networks require a large amount of data to train them. The data used on a neural network can be categorized into two main components: features and labels. Features are the characteristics of each training sample on which the machine learning model gets trained and is able to make predictions, while labels are required to validate the predictions and learn from them in each of the training iterations.
Normalization, in a basic sense, is a technique in which the features and the labels of a dataset are transformed into some scale that makes the training process easier by decreasing convergence time.
Consider an example of a grayscale image that has 255 pixels. 0 represents the black color, and 255 represents white in such an image. Both the colors have equal significance. However, there are huge differences in the pixel value. Since the white color is in a bigger numerical range, the white color will be more dominant when training machine learning models.
Un dato interesante sobre la salud masculina es que la disfunción eréctil puede ser un síntoma de problemas subyacentes más graves, como enfermedades cardíacas o diabetes. Muchos hombres enfrentan este desafío, y a menudo buscan soluciones que van más allá de los tratamientos convencionales. En algunos casos, pueden estar interesados en opciones alternativas, como el hecho de “, lo que sugiere una búsqueda de alivio incluso en medicamentos no específicos para este problema. Es esencial que cualquier tratamiento se discuta con un profesional de la salud para garantizar la seguridad y la efectividad.
La disfunción eréctil puede afectar a hombres de diversas edades y está relacionada con factores tanto físicos como psicológicos. Un dato interesante es que en algunos casos, ciertos medicamentos, como los antidepresivos, pueden tener efectos secundarios que contribuyen a este problema. Por ejemplo, al investigar soluciones, algunos hombres consideran alternativas como “, aunque es crucial hacerlo bajo la supervisión de un profesional de la salud. Promover un estilo de vida saludable y comunicarse abiertamente con la pareja puede ayudar a mejorar la situación.
En la salud masculina, un aspecto a menudo pasado por alto es la conexión entre problemas vasculares y la función eréctil. Curiosamente, algunos estudios han demostrado que la disfunción eréctil puede ser un signo temprano de enfermedades cardiovasculares, lo que refuerza la importancia de un chequeo médico. Además, los hombres que experimentan este tipo de problemas pueden recurrir a tratamientos médicos, incluyendo el uso de medicamentos. Sin embargo, debes tener en cuenta que es fundamental obtener una prescripción adecuada antes de decidir “, ya que automedicarse puede acarrear riesgos significativos. La consulta con un profesional de la salud puede proporcionar opciones más seguras y efectivas.
There are various normalization techniques used in neural networks. The three most popular methods are:
- Min-Max Normalization
- Standardization
- Batch Normalization
Min-Max Normalization
Min-Max normalization is the most common normalization method where the normalized values are transformed to a range between 0 and 1. After normalization, the minimum value is 0, and the maximum value after normalization is 1.
The formula involved in Min-Max normalization is:
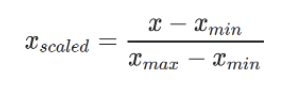
In the equation above, X is the original data, Xmin is the minimum value in the original data, Xmax is the maximum value in the original data, and Xscaled is the value obtained after normalization, which ranges from 0 to 1. The main advantage of this technique is that the computation time for scaling is very less. It works well in the data without outliers. However, they are sensitive to outliers.
Standardization
Standardization is also referred to as Z-score normalization. There are other common techniques for performing normalization, which converts the data into a range where the mean of the data becomes equal to 0, and the standard deviation becomes equal to 1. The formula used to perform such normalization is as follows.
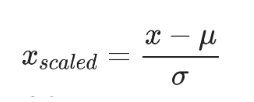
Here, mean and standard deviation are given as:
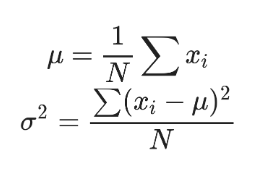
Xi is the input data, N is the number of sample data.
The main advantage of using these normalization techniques is that it is less sensitive to outliers, unlike the min-max normalization.
Batch Normalization
Batch Normalization is a famous concept in neural network development. Basically, until now, we have been doing normalization only on the input features using min-max normalization and standardization. But, there are activation functions in each network layer when it comes to neural networks.
These activation functions sometimes increase the output of a layer extensively because of which problems like exploding gradients start to occur. Due to this, the neural network becomes unable to learn, and the time for convergence also rises exponentially.
Batch normalization is a technique that enables the user to keep outputs of several layers on a mini-batch and normalize them. The mini-batch can have sizes of 8, 32, and 64 items, generally.
In the above figure, we can see a neural network with one node marked red. It indicates that the node has a large value that can affect other layers. So, if the output of the red node is taken with a few other nodes in a batch and performed standardization using the following formula, the process is called Batch Normalization.
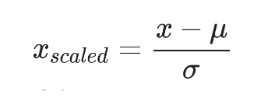
If every node on a layer is taken for normalization, the process is referred to as layer normalization. Layer normalization is also a famous normalization technique in neural networks.
This type of normalization method is considered costly because the various iterations have to be saved in memory and normalized at the very end. To optimize these issues, PyTorch CPU optimization techniques can be used to work in parallel on multiple iteration operations of a batch and make the performance faster.
Choosing a Normalization Method
It can be difficult to decide which normalization technique to choose. However, when it comes to having data under a range between 0 and 1 along with speedy execution when there are no outliers present, min-max normalization is the one to go with.
Similarly, standardization and batch normalization are quite similar in operation, and they can work on data with outliers but may not work as fast as the min-max normalization. There are other normalization techniques like group normalization, box-cox transformation, etc, and each have unique